Versioning data in Postgres? Testing a git like approach

Postgres is probably the software I love the most. Battle tested, resilient and scalable, it has been perfectly crafted in the last 30 years into one the most critical piece of technology out there. However one could complain it's not the fastest software to introduce new feature. And when something is missing you might end up being stuck, adding plugins is not easy and often impossible in the cloud, new version migration can be tricky or very slow. Moreover, a much-anticipated feature might take years to see the light of day, like table partitioning. And a notable absence in PostgreSQL is: data versioning.
Over the years, I had to add versioning in Postgres more than 10 times, and every time in a slightly different way. When I started prototyping Specfy I knew it would my 11th. Keeping history of different tables is critical to this project, so I needed a simple way to do it at scale with different tables, evolving schema and with as little maintenance as possible.
I listed alternatives and ready to use solution, but all of them had drawbacks (listed at the end) so I continued my search. I got curious about storing everything in Git. It has out of the box versioning, branching, conflict resolution, scale, etc. After a few days of digging, I realised it was a bit overkill and not the best for structured content like JSON, but it motivated me to try something new, a generic git-like versioning but in Postgres.
§How Git internal works?
I think it's important to understand how git works internally before jumping on the solution. We won't replicate all git's pattern in Postgres but try to achieve the same way to store and version objects. Please note that the following section is a simplification to make it easier to understand.
§Creating a file
A git commit flow usually looks like this:
git add myfile.txt git commit -m "initial commit" git push
Those are high level commands that hides the complexity of git. It's actually possible to write a commit using more low-level commands, like this:
# Get the hash of the file's content $hash=${git hash-object -w myfile.txt} # Add this hash with the file to object storage git update-index --add --cacheinfo 100644 \ $hash myfile.txt # Write this file to a tree # A tree is representation of a folder and its files # each folder has a tree hash # For the sake of simplicity we are still using some plumbing $treeHash=${git write-tree} # Commit the tree git commit-tree $treeHash -m "initial commit" # Update the ref to point the HEAD to the new tree git update-ref refs/heads/main $treeHash git push
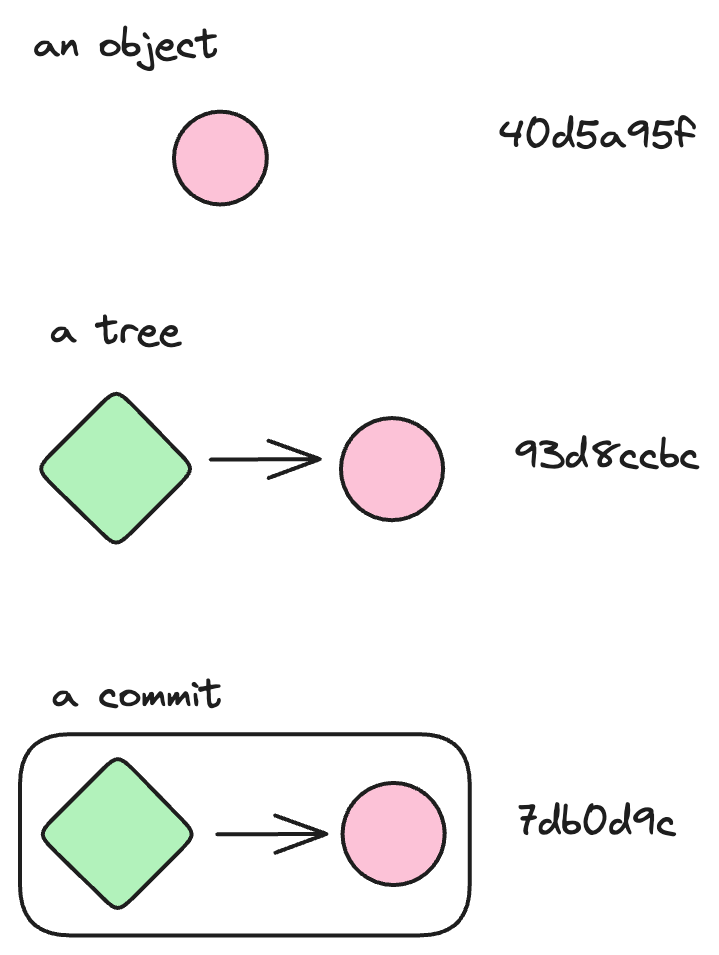
Basically at each step you get an hash: a file has an hash, a tree has an hash, a commit has an hash, a branch is a reference to hash, a tag is a reference to hash, a stash has an hash, etc...
git log --pretty=raw commit 7db0d9cefc38d263af8be1fa4b2f84531c151a60 tree 93d8ccbc3f275695ad86ca6126f0154b3973be42 parent 2f4eef4ad79ffda62f9b940d5a95fab7d17c0bd2 author Samuel Bodin <1637651+bodinsamuel@users.noreply.github.com> 1697460399 +0200
§Updating a file
Now that we understood the internals we can use the plumbing to update our file.
echo "foobar" > myfile.txt git add myfile.txt git commit -m "fix: something" git push
After our "initial commit" we now have a .git with one object and one commit. When we update the file, add it and commit it, we create a new object, a new tree and a new commit.
Then we push it to the current branch. The new commit will become the new HEAD.
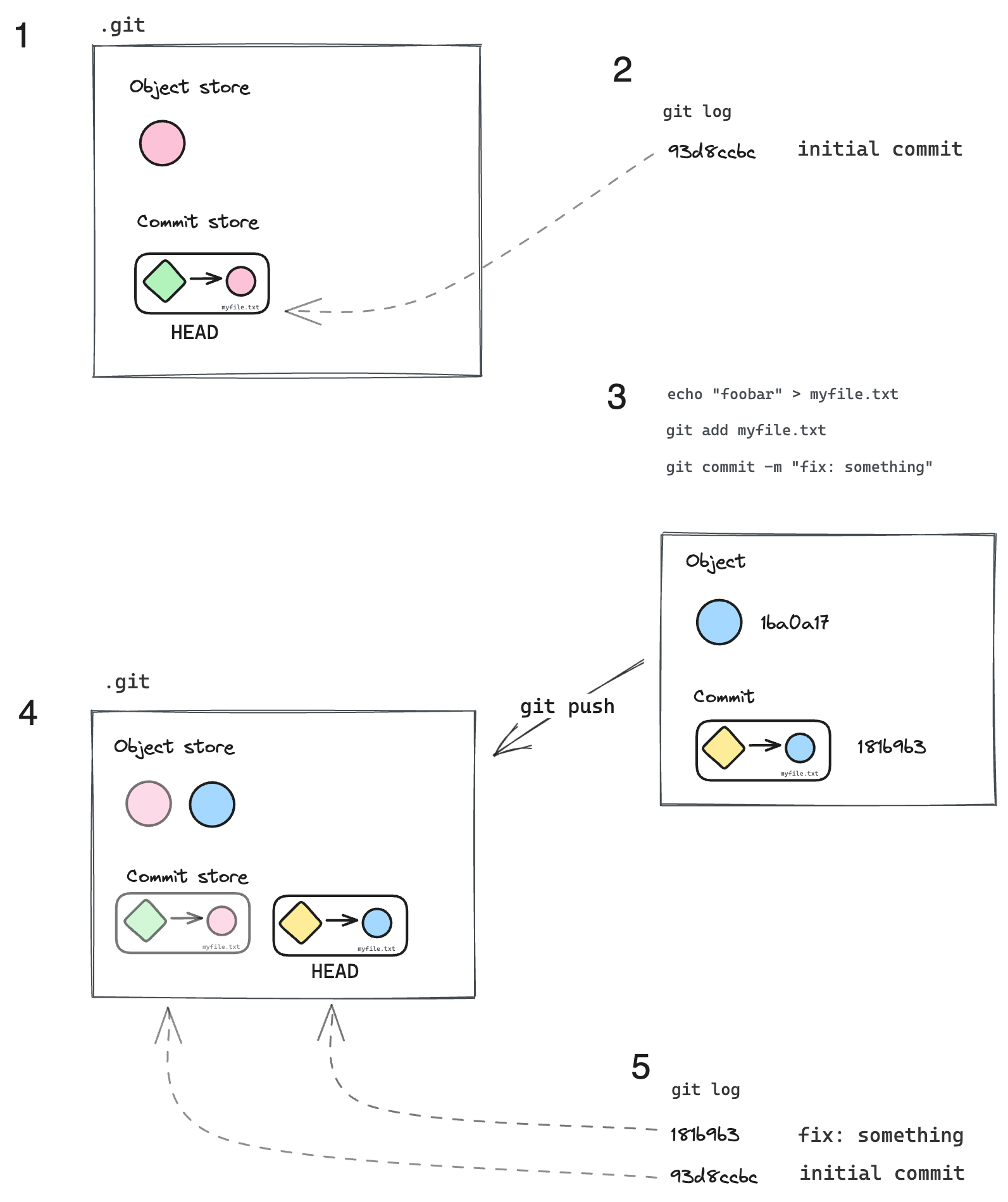
As you can see a new commit is a full copy of the file tree, and all previous objects are still there. So when you switch to a branch, checkout a commit or a file, you are getting all the information inside a single commit hash.
§Git is not storing patches
After 10 years of using Git, I realised something, it is not storing patches. Naively when you read a git diff or a pull request, you might think like me, that git is storing a diff between A and B and just displays it when needed. But in reality it stores the full file in the object storage. So each modification is just a new file (or object), described by an hash, added to a file tree and linked to a commit hash.
That also means at any given time, git has a copy of all your files since the beginning of the project. If you have rewrote a file 999 times, there is 999 times copy of this file in the object storage. That's why it can be slow to clone a git repository.
All of this combined, it has many advantages:
- You can follow history by just following an object hash and its parent hash, like a linked list
- You can navigate history instantly without having to recompute any diff
- You can switch to a branch by changing the HEAD hash
- You can rebase by changing a single parent hash
- You can diff two versions years appart because you have access to the full files
- You can revert to any version by changing a single hash
- You can rewrite history by changing a single parent hash
git clone --depth 1 allows you to fasten your clone by not downloading all the history"Storing everything at each update" sounds counter-intuitive and naive, but it is actually the most efficient solution in this scenario. Especially considering storage is cheap and computation is costly and slow.
§Implementation
Following all of this discovery, I came up with this naive and simple implementation in Postgres. I didn't use git directly because it's hard to maintain a git layer, especially in a short-lived cloud based environment, and I didn't need all the features. Calling it a git-like is definitely far fetched, but the main idea is:
- everything is stored in a global object storage
- identified by a unique hash
- each update contains the whole object
- immutable
§Blob storage
A "blob" (or binary large object) is basically a any data object in binary (e.g: text, image, video, etc.). In this blog post, I will use this name to refer to versionned objects. I didn't use the name "objects" to avoid any confusion, because it's a very generic term used in many languages and especially in Javascript.
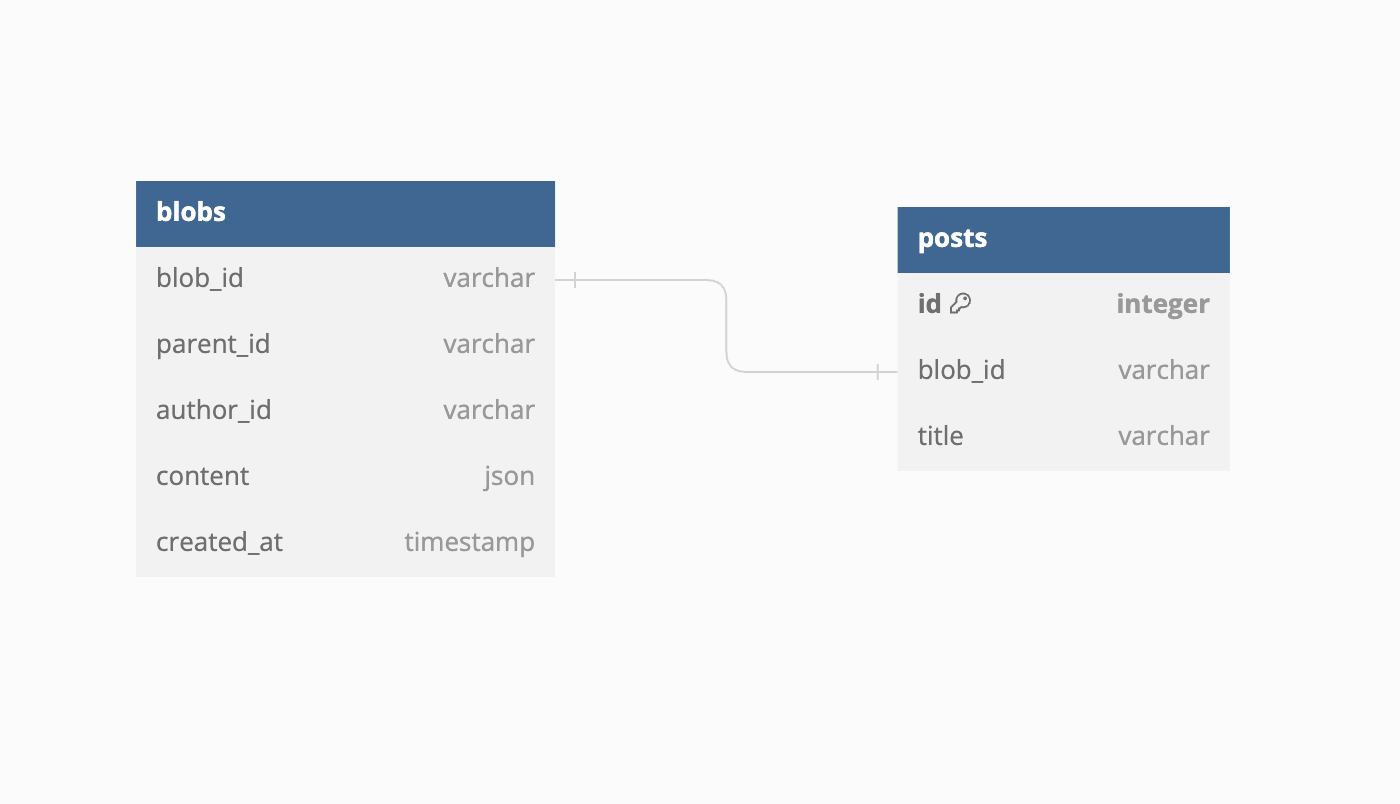
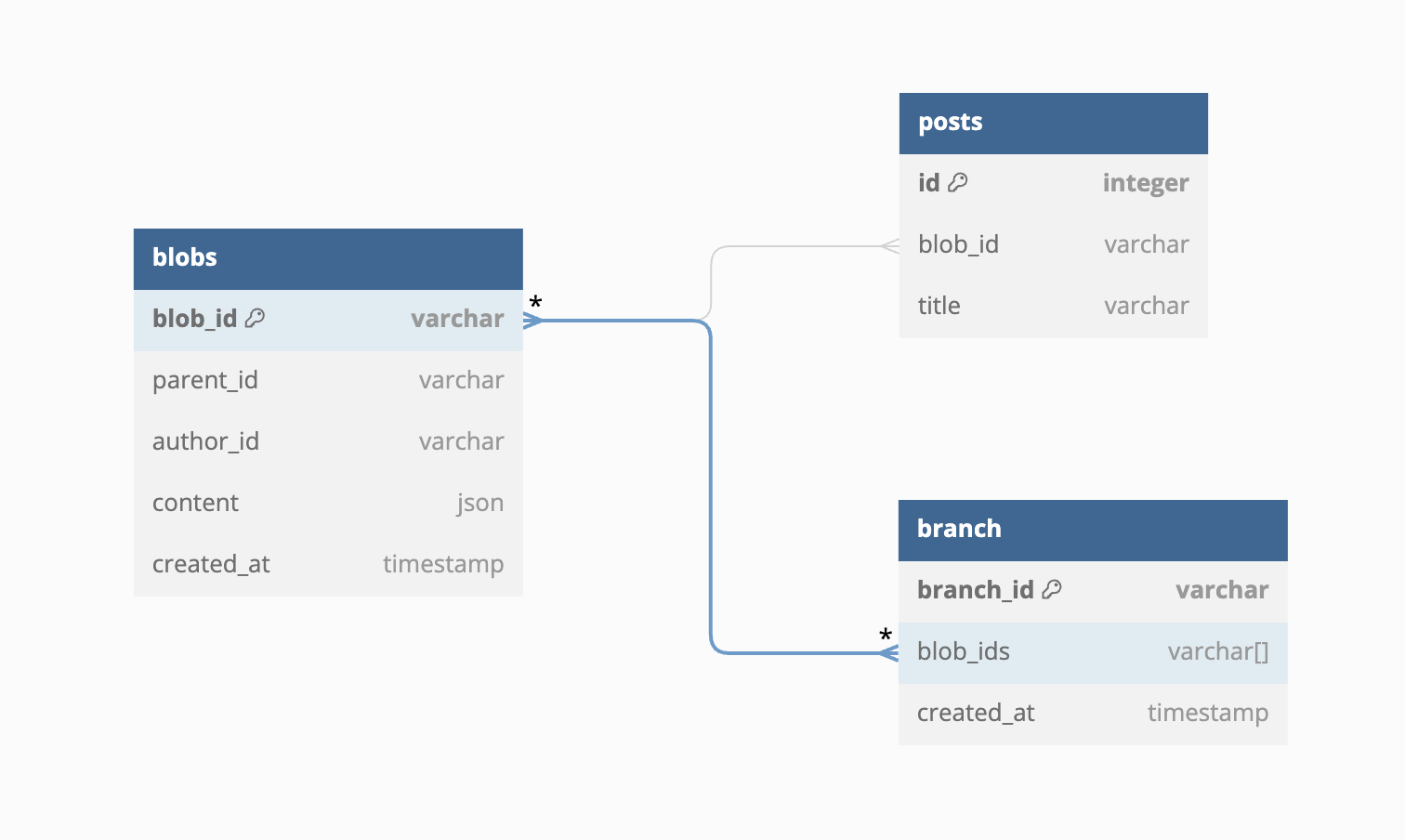
To store all our blobs, we have one table identified by an unique random id blob_id (my equivalent of a git hash). I didn't used a content hash for the id because I didn't really care for integrity at the time but it could definitely be a fingerprint instead of a random string.
The blob_id is used has a Foreign Key in every other tables to determine their HEAD, so each row has it's own HEAD.
The content column will store any type of content, we don't care what is inside it's only relevant to the associated table. Remember we are aiming to be very generic. It is a json type; we could have stored the content in a text field but it was handy to have access to the data. At some scale it might definitly be interesting to use a blob field.
The author_id and created_at capture by who and when the change was made.
§How it works?
Let's explain all of this with a more down to earth example. Let's say we are creating a blog. We have a blobs table that will contain our blobs, and a posts table will contain our blog posts.
§Creating a row
When we create a new row, we create a blob, that gives us a blob_id. We can now create a new row in the appropriate table and reference the blob_id to log where the HEAD is.
INSERT INTO blobs (blob_id, parent_id, content) VALUES ("blob_a", null, "{title: 'Foobar'}"); INSERT INTO posts (id, blob_id, title) VALUES ("post_a", "blob_a", "Foobar");

§Updating a row
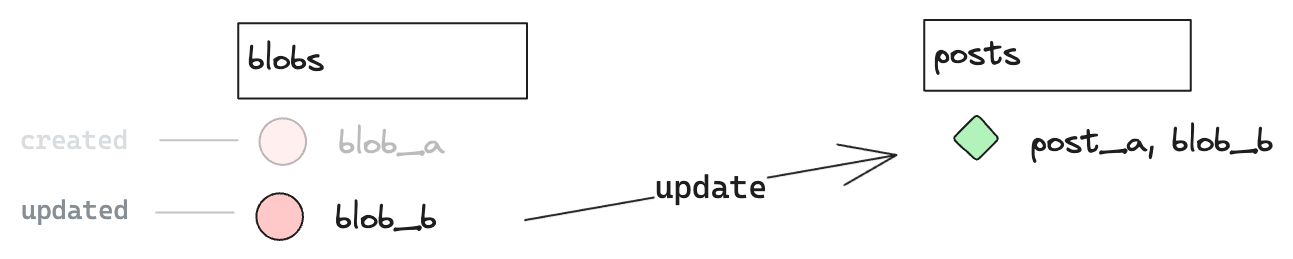
We now have a row post_a versionned by blob_a. We want to update the title, and thus create a new version.
To do that, we create a new blob referencing its parent with the new values, and update post_a.
INSERT INTO blobs (blob_id, parent_id, content) VALUES ("blob_b", "blob_a", "{title: 'Hello World'}"); UPDATE posts SET blob_id = 'blob_b', title = 'Hello world' WHERE id = 'post_a';
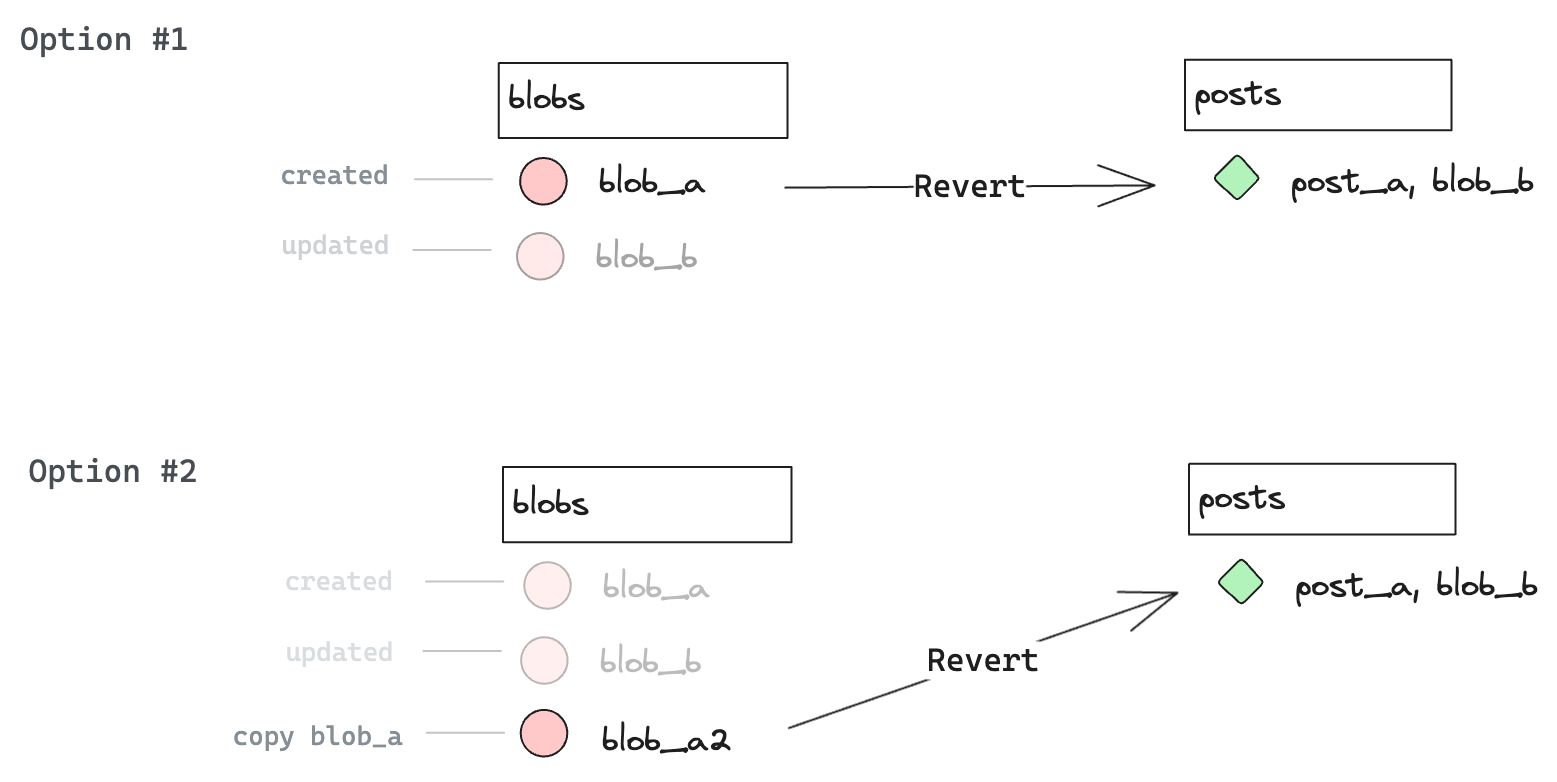
§Reverting a row
Good thing with this system, it's rather simple to go back in time and revert to a previous blob. Depending on the level of transparency you want to achieve, we can revert by simply using the hash (#1) or by copying the previous blob (#2).
§Deleting a row
Deleting a versionned object can be done in many ways depending on what you are looking for.
§Option #1 - Soft delete
The classic way. Add a deleted_at field in the posts table and update this field independently. It's quick and dirty but you don't keep history.
UPDATE posts SET deleted_at = '2023-10-20' WHERE id = 'post_a';
§Option #2 - Soft versionned delete
Add a deleted_at field in the posts table and treat delete as a regular update, so you create new blob with the field.
INSERT INTO blobs (blob_id, parent_id, content) VALUES ("blob_c", "blob_b", "{title: 'Hello World', deleted_at: '2023-10-20'}"); UPDATE posts SET blob_id = 'blob_c', deleted_at = '2023-10-20' WHERE id = 'post_a';
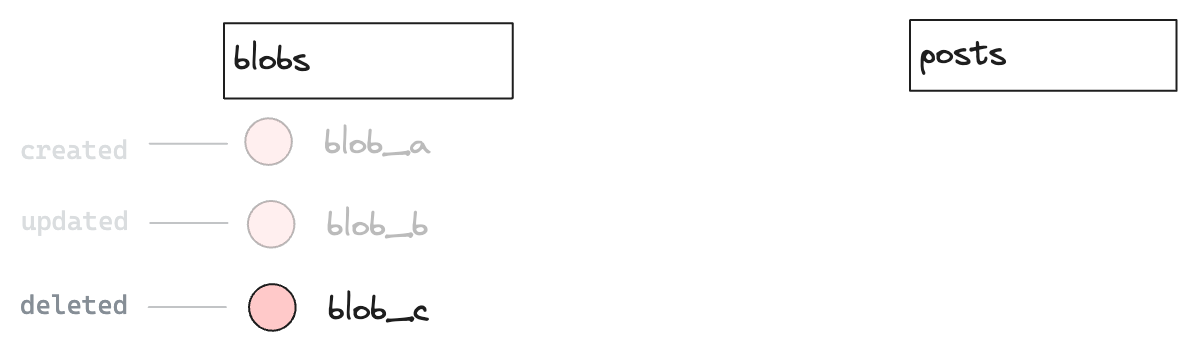
§Option #3 - Hard versionned delete
Add a deleted boolean field in the blobs table and delete the original row.
This keep the posts table clean while still keeping history for transparency or revert.
INSERT INTO blobs (blob_id, parent_id, content, deleted) VALUES ("blob_c", "blob_b", "{title: 'Hello World'}", true); DELETE posts WHERE id = 'post_a';
§Option #4 - Full hard delete
The whole point of this system is to keep history so it's a bit counter intuitive to hard delete everything, except to be compliant with GDPR (and local alternatives). For this case I would recommend adding another column to identify the organisation_id or user_id so that global deletion doesn't require listing all object ids.
DELETE blobs WHERE content->>'id' = 'post_a' ; DELETE posts WHERE id = 'post_a';
§Listing versions
If you want to build a way for your user to list versions, revert or diff in the past it's rather straigth forward.
You might want to optimise the query by creating an index with fields your regularly filter with. On my side, I choosed to duplicate the columns with the classic type + type_id.
SELECT * FROM blobs WHERE content->>'id' = 'post_a' ORDER BY created_at DESC
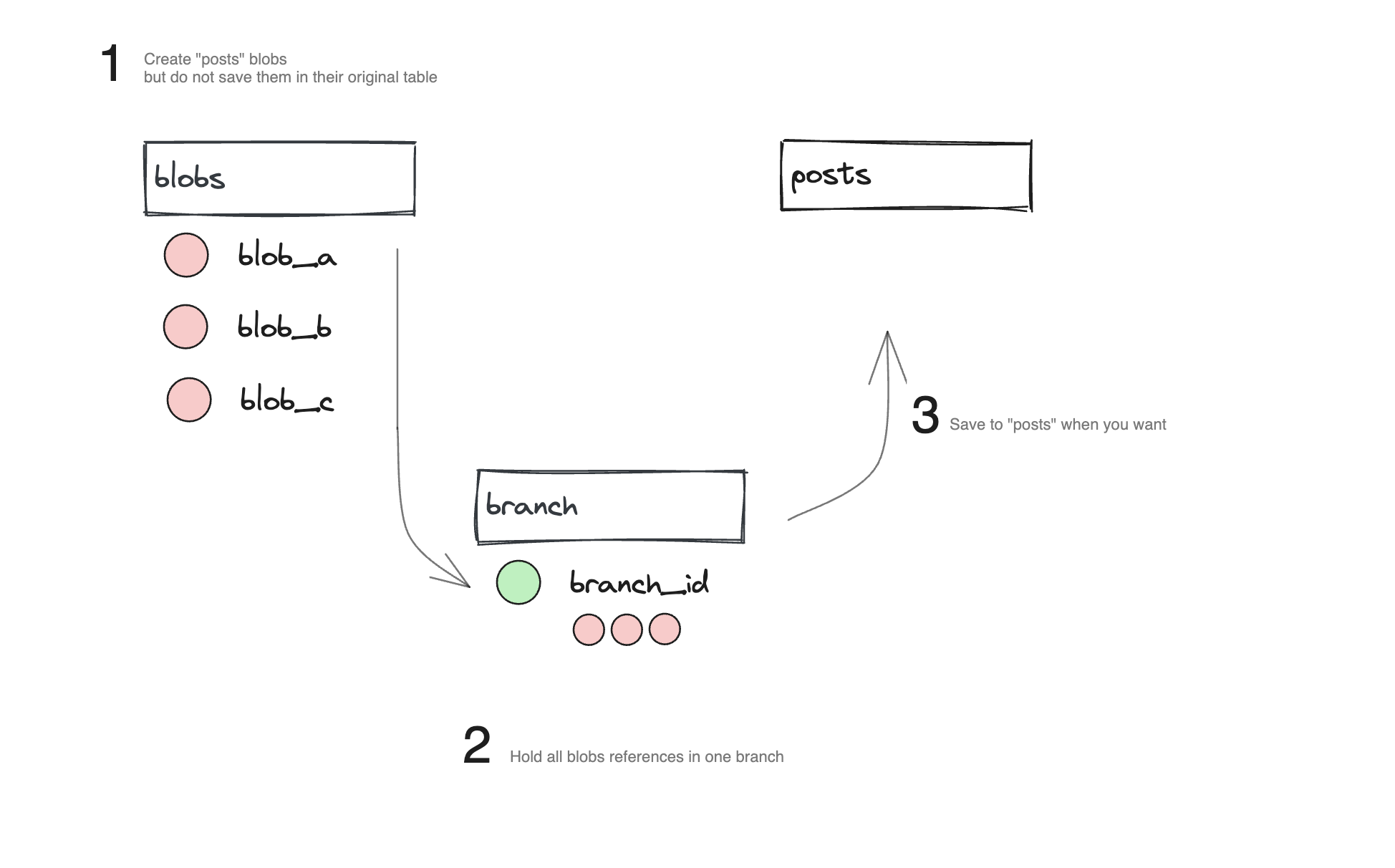
§Batching
A concept of branch or pull request can be easily replicated with an additional table. This table "branch" has a blob_ids array column that will hold many blob_id. Those blobs are not created in the source table until we decide to do so.
This is very handy to batch multiple updates to many different objects, or to allow the creation of multiple new objects in a single transaction. Specfy use this to allow users to modify everything, create a batch of change that is reviewable and diffable, like a pull request but for content.
§Table migration
Now you might be wondering, we have N copies of our data, but only the original table has a versionned schema. If we add or drop a column, what happen to my now outdated blobs?
You have multiples choices here:
§Versionned blobs
Store the table version in the blob (or the date of last migration for example) to be able to determine if the schema is still compatible or not. This can help to adapt the API or UI that is built on top of this data, but requires keeping a strategy for all schema version. And not all schema version are incompatible, for example adding a new nullable column doesn't change anything to the previous blobs.
I do believe it's the hard way, and something you wouldn't do anyway with other alternatives.
§Schema migration + Data migration
Another possible way of dealing with migration: when you migrate your table, you also migrate your data, the data being basically a copy of the schema it would be the same migration translated to JSON.
-- #1 Adding a nullable column -- Doesnt require additional fix for the data ALTER TABLE "posts" ADD COLUMN "description" VARCHAR(250);
-- #2 Dropping a column -- Requires us to also delete the field in the blobs ALTER TABLE "posts" DROP COLUMN "description"; UPDATE "blobs" SET content = sub.next FROM (SELECT id, content::jsonb - 'description' AS next FROM "Blobs") AS sub WHERE "blobs".id = sub.id;
You might understand now that this the biggest drawback to this solution. The problem of schema drift exists with all versioning solution but this might be one of the slowest. And updating millions/billions of rows can range from slow to impossible, so you might want to do it asynchronously or find another way to deal with it.
For example, in Specfy, I have an array of ignored fields, so that when I merge an old blob into a row I can just omit some fields at insert time.
// Pseudo code // List of previously existing fields that are now dropped const ignored = ['description']; // select the row const row = SELECT * FROM "blobs" WHERE blob_id = "blob_a"; // filter deleted columns const filtered = omit(row.content, ignored); // Update the original table UPDATE `posts` ${...filtered} WHERE id = row.content.id;
§Conclusion
I feel like it's a nice alternative to what we often do. It's easy to use and agnostic. Want to version a new table? Nothing else to do, the system is already there. All the versioning can be done within a single system, in a single transaction. One table, no other API, no other system to maintain. It scales with your Postgres and can eventually be partionned or sharded.
It has a major drawback, the migration of data. This is a common issue with all versioning system, but it's especially complicated when deleting or updating a column type. If you plan on modifying the schema very often, it might not be the best choice.
This is currently used by Specfy to version components, projects, documents, etc. With that, we created a notification system that always point to the appropriate version in time without duplication. Our revisions feature (pull request equivalent) was also built on top of this, it allows users to create temporary workspace, where they can branch from the HEAD of any data objects, update it, diff it, and merge it when they are are ready.
§Alternatives in Postgres
§In-Table versioning
This is the Wordpress way of doing thing. You have a posts table with a column version and SELECT the maximum version.
It's simple and doesn't require maintaining multiple schema or ressources. However it has massive drawback in term of performance, and query simplicity. The table will inevitably grow, and SELECT needs to have an order by which can make joining/grouping/aggregating harder or slower.
§Outside versioning
You can use a NoSql database or even filesystem to version your objects, which can double as backup. However you now need to maintain another API and storage which can be down or require independent maintenance. And you are even at bigger risk of schema drift.
§Copy table versioning
This is the most simple and efficient alternative. Create a quasi equivalent copy of the table your are versioning, migration is almost 1:1.
However you still need to add metadata fields, disable or rename primary key to allow the same id to be inserted multiple times.
And you obviously need one table per versionned table.
§Additional questions
§Why not using only the "blobs" table directly?
For many reasons:
- this table is not optimised for querying except by
id. - table will grow subsequently so any other mean of query will be slower and slower over time
- indexing other fields requires
jsonbdata type, that is slower and heavier in memory - foreign key checks in
jsonare lost jsonsyntax is not that well supported in all the tooling
§Why do you spread the fields in the end table and not just copy the json?
Basically for the same reason as the previous question. Jsonb in Postgres is nice and performant but will always be slower than regular access. You also loose foreign key checks and it's simply easier in most tooling.
Having regular fields allow us to control the schema with regular tools.
§Is there any database alternatives or extension?
For me not using Postgres was not a question, but you might be in a different situation. Please mind I have not tried all those alternatives:
- Neon neon.tech (Open Source)
- Dolt www.dolthub.com (Open Source)
- temporal_tables (Postgres extension) pgxn.org
- postgresql-tableversion (Postgres extension) github.com/linz